Difference between revisions of "Lex Tutorial"
Jump to navigation
Jump to search
| (8 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
[[File:Compilation phases.png|thumb|Phases of Compilation]] | [[File:Compilation phases.png|thumb|Phases of Compilation]] | ||
| − | During the first phase the compiler reads the input and converts strings in the source to tokens. With regular expressions we can specify patterns to lex so it can generate code that will allow it to scan and match strings in the input. Each pattern specified in the input to lex has an associated action. Typically an action returns a token that represents the matched string for subsequent use by the parser. Initially we will simply print the matched string rather than return a token value.<sup>[1]</sup> | + | During the first phase, the compiler reads the input and converts strings in the source to '''tokens'''. |
| + | * With '''regular expressions''' we can specify '''patterns''' to lex so it can generate code that will allow it to scan and match strings in the input. | ||
| + | * Each pattern specified in the input to lex has an '''associated action'''. Typically an action '''returns a token''' that represents the matched string for subsequent use by the parser. | ||
| + | * Initially we will simply print the matched string rather than return a token value.<sup>[1]</sup> | ||
==Lex == | ==Lex == | ||
| Line 10: | Line 13: | ||
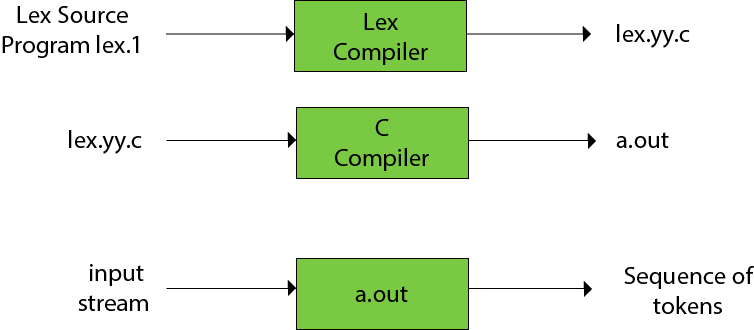
* Firstly lexical analyzer creates a program '''lex.l''' in the Lex language. Then Lex compiler runs the '''lex.l''' program and produces a C program '''lex.yy.c.''' | * Firstly lexical analyzer creates a program '''lex.l''' in the Lex language. Then Lex compiler runs the '''lex.l''' program and produces a C program '''lex.yy.c.''' | ||
* Finally C compiler runs the '''lex.yy.c''' program and produces an object program '''a.out.''' | * Finally C compiler runs the '''lex.yy.c''' program and produces an object program '''a.out.''' | ||
| − | * '''a.out''' is lexical analyzer that transforms an input stream into a '''sequence of tokens.''' <br> | + | * '''a.out''' is lexical analyzer that transforms an input stream into a '''sequence of tokens.''' <br><br> |
[[File:Lex.png|center| Running Lex Programs ]] | [[File:Lex.png|center| Running Lex Programs ]] | ||
| Line 29: | Line 32: | ||
<hr> | <hr> | ||
| − | 1. web: https://www.epaperpress.com/lexandyacc/ | + | 1. web: https://www.epaperpress.com/lexandyacc/index.html [ LEX & YACC TUTORIAL by Tom Niemann ] <br> |
| − | 2. web: https://www.javatpoint.com/lex | + | 2. web: https://www.javatpoint.com/lex |
Latest revision as of 13:41, 3 August 2021

During the first phase, the compiler reads the input and converts strings in the source to tokens.
- With regular expressions we can specify patterns to lex so it can generate code that will allow it to scan and match strings in the input.
- Each pattern specified in the input to lex has an associated action. Typically an action returns a token that represents the matched string for subsequent use by the parser.
- Initially we will simply print the matched string rather than return a token value.[1]
Lex
- Lex is a program that generates lexical analyzer. It is used with YACC parser generator.
- The lexical analyzer is a program that transforms an input stream into a sequence of tokens.
- It reads the input stream and produces the source code as output through implementing the lexical analyzer in the C program.[2]
The function of Lex is as follows:
- Firstly lexical analyzer creates a program lex.l in the Lex language. Then Lex compiler runs the lex.l program and produces a C program lex.yy.c.
- Finally C compiler runs the lex.yy.c program and produces an object program a.out.
- a.out is lexical analyzer that transforms an input stream into a sequence of tokens.

The Lex Format
A Lex program is separated into three sections by %% delimiters. The format of Lex source is as follows:
{ definitions }
%%
{ rules }
%%
{ user subroutines }
Here
- Definitions include declarations of constant, variable and regular definitions.
- Rules define the statement of form p1 {action1} p2 {action2}....pn {action}. Where pi describes the regular expression and action1 describes the actions what action the lexical analyzer should take when pattern pi matches a lexeme.
- User subroutines are auxiliary procedures needed by the actions. The subroutine can be loaded with the lexical analyzer and compiled separately.
1. web: https://www.epaperpress.com/lexandyacc/index.html [ LEX & YACC TUTORIAL by Tom Niemann ]
2. web: https://www.javatpoint.com/lex