Difference between revisions of "MPLab1 Addition"
Jump to navigation
Jump to search
| Line 1: | Line 1: | ||
==32-bit Binary Addition Step by Step == | ==32-bit Binary Addition Step by Step == | ||
* Specify the size and number of code, data, and stack segments | * Specify the size and number of code, data, and stack segments | ||
| − | ''' | + | ''' .model small <br> |
| − | .model small <br> | ||
.stack 100H | .stack 100H | ||
''' | ''' | ||
Revision as of 22:47, 17 September 2023
32-bit Binary Addition Step by Step
- Specify the size and number of code, data, and stack segments
.model small
.stack 100H
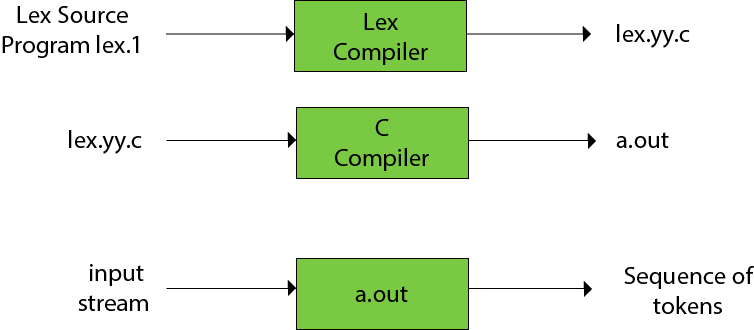
- The lexical analyzer is a program that transforms an input stream into a sequence of tokens.
- It reads the input stream and produces the source code as output through implementing the lexical analyzer in the C program.[2]
The function of Lex is as follows:
- Firstly lexical analyzer creates a program lex.l in the Lex language. Then Lex compiler runs the lex.l program and produces a C program lex.yy.c.
- Finally C compiler runs the lex.yy.c program and produces an object program a.out.
- a.out is lexical analyzer that transforms an input stream into a sequence of tokens.

The Lex Format
A Lex program is separated into three sections by %% delimiters. The format of Lex source is as follows:
{ definitions }
%%
{ rules }
%%
{ user subroutines }
Here
- Definitions include declarations of constant, variable and regular definitions.
- Rules define the statement of form p1 {action1} p2 {action2}....pn {action}. Where pi describes the regular expression and action1 describes the actions what action the lexical analyzer should take when pattern pi matches a lexeme.
- User subroutines are auxiliary procedures needed by the actions. The subroutine can be loaded with the lexical analyzer and compiled separately.
1. web: https://www.epaperpress.com/lexandyacc/index.html [ LEX & YACC TUTORIAL by Tom Niemann ]
2. web: https://www.javatpoint.com/lex